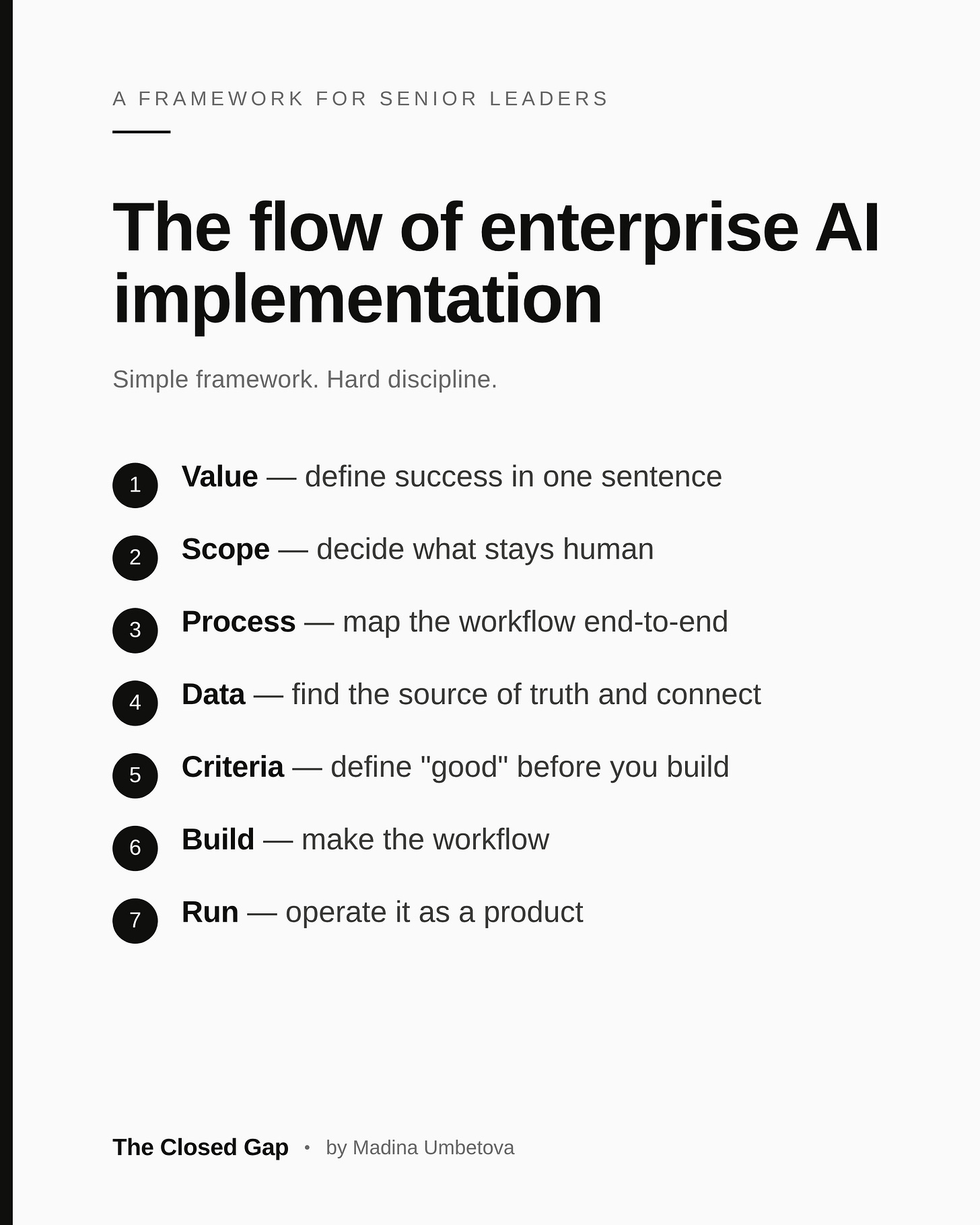
The seven steps of enterprise AI implementation
Enterprise AI implementation takes 7 steps. Consultants bill six figures for three of them, forgetting about the rest. Here is the whole map, from the commercial operator's chair.
A couple of weeks ago I sat in a pitch for an enterprise AI platform. Six figures, before anyone had touched our data. The demo walked through a polished case study built on a burger chain: order forecasting, staffing, the works. It looked impressive in the room.
I left thinking about one number. The gap between what they were asking for, and what I could already build myself with tools that cost a fraction of that. A year ago that gap was a real moat. Now it has mostly closed. The technology layer matured to the point where a non-developer who understands a business can operate it directly.
That is why I started writing here. I want to show a senior commercial operator what the work actually involves, in plain language, so you can tell a real implementation from a good demo.
This first issue is the whole map. Seven steps. I use a version of this to walk any AI initiative I am shown, including the ones in expensive slide decks.
The one idea that changes everything below
An AI workflow is a product, and it carries a product's full cost. An owner. Monitoring. Retraining when the model or the data shifts. Eventual replacement. The build is roughly 30 to 40 percent of the lifetime cost. Running it is the rest.
A big software rollout, an ERP for example, also needs maintenance and an owner. The difference is what degrades. Once an ERP is configured it mostly stays put. An AI system drifts even when you change nothing, because the model gets updated, the data ages, and the real world moves under it. Accuracy that was fine in March is quietly wrong by September unless someone is watching. So the running discipline is heavier, and it is the part almost every plan underfunds. Hold that in mind as you read the steps below. It changes how each one gets scoped.
The seven steps
1. Value
Define what success means in one sentence, without using the word "AI."
What decision are you improving, or what task are you removing? Whose KPI moves, and by how much? What is that worth in money or time, measurably? And at which level is the value visible? If the saving only shows up at a corporate KPI three layers up, the team doing the work carries the cost while someone else books the win. That kills adoption faster than any technical problem.
A real value sentence sounds like "the regional managers spend two days a month assembling the commercial review by hand, and I want that down to an afternoon, with the same accuracy." No jargon. If you cannot write it on a napkin, you are not ready to start.
2. Scope
Decide what gets automated and what stays human.
Some processes are slow because nobody ever fixed them. Data hunting, document parsing, status reports, summarising long threads. Fair game. Other processes are slow on purpose. Regulatory checks, judgment calls, the conversation where a key customer needs to hear a human voice, anything irreversible. Those stay human. Some friction is a feature, and the techno-optimist who automates everything learns that the expensive way.
3. Process
Map the chosen workflow end to end. Every handoff, every input, every output, every decision point.
Stay tight to the value you defined in step 1. Map one path to one outcome, and resist the urge to document the whole organisation. The first thing you find is that no single person holds the full process. Part of it lives in one person's habits and has never been written down. Where it has been written down, the document is often a procedure from years ago that no longer matches what people actually do. Treat that discovery as part of the work. It is the most useful thing the exercise produces, because you cannot automate a process nobody can describe.
4. Data
Find the data the process actually needs, and where it really lives. In most industries this is the most painful step of the seven, and the one that quietly sinks projects.
The data lives in PDFs, in someone's Excel on a laptop, in a monthly report a person rebuilds by hand, in email threads, and in the head of the rep who "just knows" which price list is current. In a lot of industrial and regulated businesses the worst of it lives in scanned documents: certificates, lab reports, supplier specs, contracts signed a decade ago. For each source, settle which one is authoritative, which is stale, which is of unknown quality.
Here is the part that changed recently, and a fair share of why I bother writing about this. You no longer need a data-warehouse project to read messy sources. Modern models handle them directly. For scanned documents specifically, the simplest move is to upload the file straight into Claude and ask it to pull the contents into a clean table. It reads scans, photographs of documents, and mixed layouts surprisingly well. For high volume, or where an error is expensive, a dedicated document-extraction service does the same job at scale with validation built in. Whichever route you take, check the output on a sample before you trust it. Poor scans, dense tables, and handwriting are still where these tools make mistakes.
The bottleneck has moved. Reading the data is now the easy part. The hard part is deciding which version of the truth wins when two sources disagree.
5. Criteria: define "good" before you build
This is the step that most failed implementations skip entirely, and the reason they fail.
What does a right answer look like? Show real examples. What is the human baseline you are measuring against, in accuracy, speed, and cost? Who labels the ground truth? Who has the authority to say the system is good enough to ship? How will you watch quality after launch?
Lock these answers before a line of code is written. A demo always looks brilliant, because in a demo there is no ground truth to fail against. Production is where the absence of criteria gets exposed.
6. Build
Now you build the workflow. The shape follows the value you defined.
It might augment a human, drafting and suggesting and summarising for a person to review. It might automate an action end to end, with safeguards. It might surface patterns from data a person could never read manually. Or it might generate something new. You iterate against the criteria from step 5 until you meet or beat the human baseline. This is the part the market sells as the whole job. It is one step of seven.
7. Run: operate it as a product
Launch is where the real work starts.
You need observability, so you can detect drift, hallucinations, and breakage before a customer does. You need governance, so there is a clear answer to who owns the decision when the agent is wrong. You need maintenance for model upgrades, prompt updates, and data refreshes. You need ownership, because someone's name has to be on this agent 18 months from now. And you need an answer to the Tuesday-evening question: when it breaks, who fixes it.
Two threads that run through all seven
The human factor. Resistance is real and usually rational. Some of it is fear, from the person whose task is automated next, or the team worried about being judged by an agent's output. Some of it is institutional memory, the "we got burned in 2019 when we shared that data" that turns out to be true. Both deserve a hearing. The operator's actual skill is telling fear apart from a legitimate concern, because both should change what you build. Pretending resistance away in a kickoff meeting solves nothing.
Governance and observability. Liability is the easy question: who is responsible when the agent is wrong, the team that built it, the business owner who handed over a broken process, or the assistant who forgot to upload a file. Most companies have not even named that question out loud. Observability is the hard one: how do you notice the agent went wrong, in what order do corrections get deployed, who is on call. Most companies have not built that layer at all. Both need answers before launch.
Where the work actually lives
Most of what consultants charge to deliver sits in steps 3, 4, and 6: the mapping, the data plumbing, the build. Most of what determines whether the thing survives contact with reality sits in steps 1, 2, 5, 7, and the two threads. That is the gap between what gets sold and what actually works, and it is wide enough to drive a six-figure invoice through.
You do not need me to walk these steps. You can walk them yourself against any initiative on your desk. Take the next AI pitch you are shown, internal or external, and ask which of the seven it actually addresses. In my experience most of them skip 1, 2, 5, and 7. They demo step 6 and call it a solution.
What this newsletter is
I am a commercial operator with 27 years of experience across crop protection, healthcare, chemicals, and distribution, currently running a large global portfolio. I spent the last stretch closing the gap between having an idea and getting it built, the gap that usually sits with IT or a vendor. This is where I write down what I find, for senior leaders who would rather think and build than only buy.
One issue every Sunday. Real methodology, in plain language. Nothing here assumes you can code.